

These days, recruiters are flooded with resumes. Some of them are good, some of them are great, and some of them are just plain bad. Due to thousands of resumes or may be lakhs in some cases, recruiter may have to face multiple challenges during the initial shortlisting/screening process.
Few of the challenges are
– If you are sourcing from Internet, you will get thousands of resume for a single position.
– Generally recruiters also has their own database but may not be search-able because they are just word document on there hard drive.
– It is difficult to match the job description with the bunch of resumes. Recruiter has to manually open each file and read through to figure out the match. This is time consuming and complex.
So how can we ease the work of the recruiters ?
Career Site Manager is the one complete recruitment solution build by Naukri. To know more about what is Career Site Manager (CSM). Click here.
The capability to parse single/bulk resume is part to Career site manager (CSM). CSM’s resume parsing software is a fast, efficient, and highly useful tool that works the way recruiters work.
Resume Parsing (also known as CV Parsing, Resume Extraction, CV Extraction) is the conversion of a free-form CV/Resume document into structured information suitable for storage, reporting and manipulation by a computer. The most common CV/Resume format is MS Word which despite being easy for humans to read and understand, to a computer they are just a long sequence of letters, numbers and punctuation. A Resume Parser is a program that can analyse a document, and extracts from it the elements of what the writer actually meant to say, which in the case of a CV usually are the skills, work experience, education, contact details and so on.
Resume parsing is a plays a vital role in maximizing the efficiency and time saving.
Where is Resume Parser used in CSM ?
It is used to parse resumes coming into CSM via ‘Upload CVs in Bulk’, ‘Upload Multiple CVs’ and ‘Upload CVs from Email’ features in CSM. Various fields like Name, Email, Current Designation, Current Location, Experience, Key Skills, Education etc. are extracted from the resume automatically.
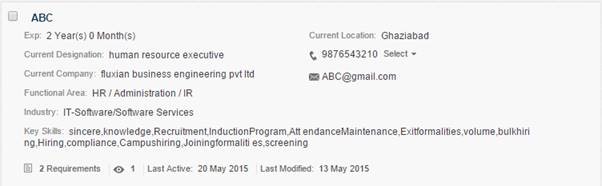
The Resume Parser tries to predict values from the resume document based on past statistics and learning.
How do we measure the performance of Resume Parsing?
There are two metrics to measure the efficacy of a parser- Coverage and Accuracy.
Coverage is a measure of how many times we are able to predict a value, and Accuracy measure how often the predicted value is correct. No resume parser available in the market has 100 % coverage or 100 % accuracy on all fields.
How it works?
A Resume document when read by our system is nothing but a blob of text to it. The process of extracting structured information from it involves extracting out patterns from text which may contain valuable information like name of company, current designation etc. Once you have extracted out the frequently occurring pattern, the parser needs to know which phrase among the pattern qualifies to be one of the structured information.
Why CSM’s resume parser provides better coverage and accuracy?
There are a huge number of Companies and education institutes in the world. Similarly, there are huge number of Key Skills, Designation, and Location etc. compared to other parsers\tools available in the market, we have a richer library of these fields, especially from Indian context because we are able to leverage the huge database of Naukri.com. Still there will be limitations, as it is not be possible for the system to recognise 100% of the companies, locations, education institute etc. present in the world.
Fields like the industry the candidate belongs to or the functional area his profile is in can be handy filters for a recruiter. This is an information which candidates typically won’t write in his CV. However, we are able to extract this out by inferring it from other signals in the CV.
What is the current performance of Resume parser integrated in CSM?
In CSM we have invested heavily on the parser and current capabilities of the resume parser based on internal benchmarking is as follows:-
| Metric\Field | Name | Mobile | Current Location | Current Company | |
| Coverage | 87% | 86% | 92% | 96% | 73% |
| Accuracy | 88% | 97% | 97% | 79% | 91% |
| Metric\Field | Current Designation | Key skills | Total Experience | Objective | Profile Summary |
| Coverage | 79% | 97% | 86% | 61% | 57% |
| Accuracy | 82% | 69% | Range given below | 86% | 85% |
| Total Experience | 0% Error | +/- 10% Error | +/- 20% Error | +/- 30% Error |
| Accuracy % | 46% | 64% | 70% | 75% |
| Education Details | Course | Specialization | Institute | Year of Passing |
| Coverage | 47% | 55% | 48% | 45% |
| Accuracy | 83% | 61% | 78% | 81% |
The above coverage and accuracy is calculated over a large set of resume. Also, accuracy and coverage for resume mapped from known email sources like emails sent from naukri.com is much more compared to some other email sources. Total Experience has a percentage of error associated with it as it is a numerical value. Education details covers both Under Graduation and Post Graduation.
If you are a recruiter and not currently using Career Site Manager, you should be.
By using CSM, you’ll:
- Save time
- Maximize efficiency
- Match candidates with the most suitable opportunities for their skill sets
- Meet client requests faster and with better candidate matches
And last but not least, a brief report of the file formats supported by Resume Parser :
Document formats: doc,docx, rtf, txt, pdf, odg.
Container formats: pst, zip, rar
Want to work on similar cutting edge products and technologies, join us.



 The All-New Naukri iOS App (6.0)
The All-New Naukri iOS App (6.0)