

Technology upgrade rollouts are too frequent these days, so are the requirements and expectations from a product. We need to keep up with this pace to take advantage of the changes and enhancement in technology and also able to fulfill the needs and expectations of a user. For this the product should be robust and architecture should be scalable to meet the growing demands from a product.
So we took a step to upgrade elasticsearch from v1.x to 2.x. Let’s start with a small brief on why we decided to go for upgrade and architectural changes.
Why we need to do this?
To take advantage of performance improvements done in version 2.x
- Memory and cache management : Comparing to version 1.x version 2.x has better management. Handling cache is now easier. Version 2.x has introduced auto-caching behaviour. In the older version everything which was cacheable was cached. This had a serious effect on performance due to thrashing of large size of cache during cache eviction. This behaviour has been changed to auto-caching behavior which is smart enough to determine what need to be cached.
- Better filtering: Filter query cache is updated rather than rebuilding cache again when a new document is indexed. This removes the overhead of recomputation of cache. Cache expiry is no more a headache now, filters are real time !!
- Improved parent-child relationships: Elasticsearch now maintains a map of which parents are associated with which child which makes query joins faster.
There are a lot more improvement other than which I mentioned above. Let us now continue on why we need to do this.
Deal with a very fast growing data
- The data was growing at a very high rate and we need to deal with this large data and heavy traffic. Our existing architecture was just good enough to handle this but not robust enough to handle this on a long run as data was expected to grow further and so was the traffic.
- What we were about to deal with?
- Approx 2 million index requests per day expected to grow 2 times
- Approx 3 million search requests per day expected to grow by 3-4 folds
- Why it was going to be difficult? Will talk about this in “Challenges” section.
Architectural changes
- To be able to handle large data, huge amount of traffic, improve search performance and deal with existing issues it was required to redesign the index architecture.
Challenges / Issues
We had been facing some major issues with our existing setup.
- Fair amount of slow queries: There have been slow queries which involved child indexes. Another reason for slow queries was due to existing methodology of filter caching in elasticsearch version 1.x
- Rigid non-scalable index architecture: Our existing index architecture was too rigid and non scalable. We had two indexes with 100 shards per index. The parent-child relationship on indexes had grown till the level of grand child.
- Stale data: Since single index was holding enormous amount of data, refreshing index had become a pain. We had to rely on auto refresh option elasticsearch configuration which refreshes index every 30sec. So in worst cases user were able to see new data only after 30sec.
- Exploding size of index aliases: With the increase in number of users the size of alias has grown to way above than it should be. This had made the search cluster unstable.
- Large size of cluster state: Having a lot of aliases and dynamic properties for an index lead to a large cluster state. Cluster need to updated and sent over to all the cluster nodes each time there is a change in it. Large size of cluster state lead to performance hits and sometimes also caused to slow down a node to almost not-responding state.
- Tightly coupled search code with application code: Search code was tightly coupled with application. All the search logic was part of application code and hence it was difficult to perform partial rollouts and upgraded.
Dealing with Challenges / Issues
Existing architecture
Our existing architecture had 100 shards per index. This made it a very rigid design as shards are decided when an index is created. It is not possible to change the number of shards later. As the data grew there was a need to increase the number of shards. It was a difficult task to increase the number of shards with the existing architecture since it requires reindexing full data again after increasing the number of shards. 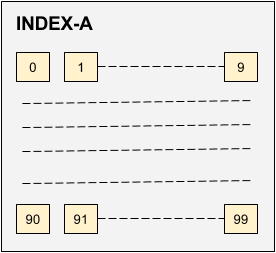
To deal with this issue of scalability we redesigned this architecture. Instead of having 1 index with 100 shards we decided to have 100 indexes with one shards per index as shown in the diagram below.

Elasticsearch internally take care of data allocation, search routing to shards. With new design we would be taking care some aspects of this in our application code, i.e. it is now the responsibility of application to determine which index is to be referred. Though it is an overhead for application but it is worth the scalability we achieve with this design. If we feel that we need to introduce a new shard we introduce a new index INDEX-A-100 with 1 shard. (without worry of over enlarging the size of some particular shard) This doesn’t require shutting down node and reindexing data.
Another major issue was a large number of aliases which resulted in large size of cluster state. Larger cluster state results in slower performance. Our existing alias structure was one alias per user. When the number of users increased from few thousands to few lakhs we started facing issue due to large cluster-state size. Any new alias creation means change in cluster state. This changed state has to be updated on all the nodes. As the size grew large, updation task started taking more that 30sec slowing down the node to almost not responding state.
To overcome this issue, it was required to reduce the cluster state size and eventually the number of aliases. Our user list is divided in 3 types.
- Users of Type A and Type B contributes to 20% of total number of users.
- Users of Type C contributes to 80% of total number of users.
Also, data of Type C users contributes to only ~20% of total data.
So we decided to route data of type C users to a single index with single alias for all users of Type C. Therefore bring down the number of aliases from ~5 lakhs to ~80k therefore reducing the cluster size by almost 80%.
Advantages of above architecture:
- Data distribution: Instead of one large index, data is distributed across multiple indexes
- Real time updates whenever required: Since the data is now distributed in 100 different indexes it is possible to refresh index immediately whenever required. In earlier case the refresh was a bottleneck since for each refresh a large size of data had to refresh which is comparatively very less now.
- Easy to scale: Ability to add new index without any downtime
Ability to migrate some data from larger indices to smaller ones (not possible in shards)
Overhead of above architecture:
- Difficult to maintain: Instead of one index there are multiple indexes to look into
- Difficult to update index properties/settings: Require scripts to do update settings or properties of indexes. To overcome this, we created scripts that take required data as arguments and perform the actions on all the similar indexes. The scripts are capable enough to make changes to selective index, range of indexes or all the indexes.
- Overhead on application: It’s now the overhead on application to decide routing to index rather than elasticsearch deciding to route to a particular shard.
Child-index types
Another issue was, the level of child index types had grown to the level of grandchild. Deeper the child level slower the search queries. Nested aggregations involving child took heavy performance hit.
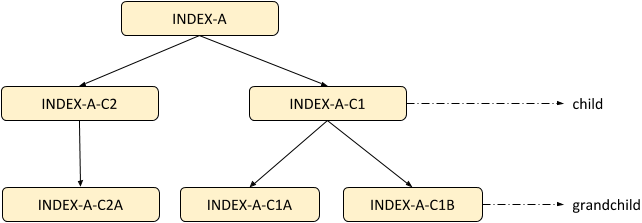
The figure above shows the old index type relationships.
- INDEX-A has a child type INDEX-A-C1 which in turn have two children INDEX-A-C1A and INDEX-A-C1B. We should avoid such level of hierarchy wherever possible.
- INDEX-A has properties common to both INDEX-A-C1 and INDEX-A-C2.
- INDEX-A-C1A had 1 to 1 mapping with INDEX-A-C1
- INDEX-A-C2A had 1 to 1 mapping with INDEX-A-C2
The reason to create child indexes INDEX-A-C1A, INDEX-A-C2A was to take advantage of partial document update feature of elasticsearch. To make partial updates it is necessary to store index. Storing index leads to higher disk space consumption and therefore only those properties which are updated frequently were part of these child indexes.
Even though we were able to save some space by this design this leads to slow down queries which involved querying child index. The effect was more severe when doing nested aggregation involving child indexes.
To solve this we decided to split INDEX-A into two index:
- INDEX-A1 = INDEX-A + INDEX-A-C2 + INDEX-A-C2A
- INDEX-A1 = INDEX-A + INDEX-A-C1 + INDEX-A-C1A
Since INDEX-A-C1 has one to many relationship with INDEX-A-C1A; INDEX-A-C1A was kept as a child index of INDEX-A1. So, finally we have:

Gains by above changes
- No deep level parent – child relationship.
- Majority of queries are now faster as there is no involvement of child indexes.
- Ability to provide features such as search highlighting.
- When targeting an index for search it is not possible to sort result by a field of child index. With the above changes it is now possible to perform sorting by fields of index types which were initially part of child indexes because now they are part of main index.
- Since every field is now stored majority of data can be fetched from search itself and hence reduces the number database queries.
- Stored index also gives advantage of partial updates on any field.
- Introducing a new field in index and populating it for legacy data is no more a full reindex overhead. Reason being the index is stored. We can take advantage of partial update and populate just the newly introduced field with the data without the overhead of full re-indexing all documents again.
Tradeoffs
- Instead of just keeping child index as stored, complete index is now kept as stored which increases the storage size.
Search logic abstraction from main Application code
As already mentioned above search logic was tightly coupled with application code and hence was difficult for partial rollouts and search upgrades. For easy future upgrades we decided to abstract search logic as a separate application and create it as a service.
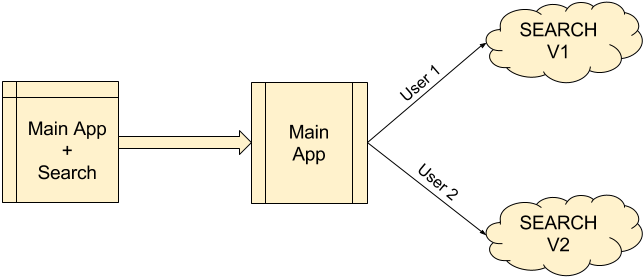
With this we are now able to perform partial roll outs, i.e. gradually moving users to upgraded search platform rather than moving all in a single go. Also it became possible to have multiple versions of search running in parallel and serving different set of users as described in the figure above.
These were the major architectural changes that we did to make the system scalable, improve search performance and tackle the issues we were facing with old architecture.
Below are some other change we have done to gain performance:
- Reduction in number of aliases. We reduced the number of aliases by grouping the data of certain type users to one particular index and having single alias for that index. In general speaking try to avoid a large number of aliases. We can even avoid using aliases completely if following the above architecture as routing is already taken care by application.
- Avoided dynamic mapping, instead redesigned the logic to use nested objects. Dynamic mapping is harmfull if the number of dynamic fields in an index type is expected to grow very high, as it was in our case.
- Reduced the size of cluster state. With the above mention two changes we were able to reduce the size of cluster state. As the size of cluster state increases the probability of instability also increases; therefore the growth of cluster state should be analyzed before hand and should be planned to keep its size to the minimal.
- According to elasticsearch documentation use of even a little amount of swap space will hamper the performance of elasticsearch. Therefore set the swappiness value on your machine running elasticsearch to minimum and if possible set it to 0 i.e. don’t use any swap space.



 The All-New Naukri iOS App (6.0)
The All-New Naukri iOS App (6.0)