

What we will be focussing on:
- Creating tag of application and deploying on kubernetes.
- Creating an immutable image
- Naukri Deployer and Endpoints
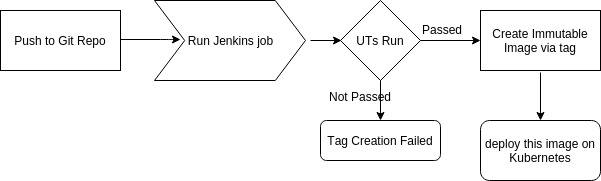
Creating a tag of Application:
Whenever we push to git repository, a jenkins job is triggered and runs UT(Unit Test Cases) on that branch (or tag). If UTs are passed create a tag and run next jenkins job to create immutable image. This new immutable image can be deployed on kubernetes and subsequently QA team can run their FT(Functional Test Cases) on that tag.
To know what is an immutable image, refer:: https://www.twistlock.com/2015/08/06/immutable-infrastructure-containers-and-security/
Reasons to Create an Immutable Image :
- Portability – container needs to be self sufficient in order to be portable.
- Predictability – with an immutable image , you can be sure that given tag of a given image will always behave similarly
- Testing
- Deployment and rollback
Creating an immutable image:
How we created an immutable image of our application:
- Identify application dependencies like PHP, apache, nginx etc and create an image having all application dependencies installed
- Identify your configuration or virtual host files and specify path to mount those confs( apache or nginx).
Eg: ./conf/sites-enabled/app1-env.conf:/usr/local/apache_ms/conf/vhost.d/app1.conf. - Identify the extensions you need like memcache or redis and similarly specify file path to mount those as well.
Eg: ./conf/memcached.ini:/usr/local/php/etc/conf.d/memcached.ini - Point your db services or any other services like elastic and define their endpoints.
Naukri Deployments:
For multiple Applications that are interconnected we needed a common deployer and also a setup that deploys all the applications at once.Thus came naukri deployer .
For this we created our own deployer and each application’s services had a separate end point defined .So for an application we segregated it’s services and code(app basically).
Deploying a tag on Kubernetes:
We need to identify the application whose tag we are to deploy on kubernetes. For which we have a repository for each application (for kubernetes deployment) which in turn has the following files.
- ns.json
- rc.json
- app-svc.json
- endpoints.json (And all other service end points required for application.)
- A namespace json will contain the namespace name and its version .
- The specifications mentioned in rc.json for your kubernetes may look like ->
“spec”: {
“nodeSelector”: {
“ni-node”: “any”
},
“containers”: [
{
“name”: “app1-app”,
“image”:“docker.naukri.com/naukri/app1:{{TAG}}”,
“env”: [
{
“name”: “ENVIRONMENT”,
“value”: “{{PROJ_ENVIRONMENT}}”
}],
“ports”: [
{
“containerPort”: 8080,
“protocol”: “TCP”
}
]
}
- app-svc.json
It would contain metadata for service and port specification for the application, thus we are deploying application as a service. - endpoints.json
Would contain endpoints for other services like memcache,redis,elastic ,db services etc. Endpoints here refer to the host and port on which your services are hosted.
Dependencies are part of codebase:
The database services endpoints along with configurations for memcache or redis are part of our codebase. If my application needs nginx then I must have nginx.conf for docker env at a specified path and similarly for apache we had the httpd.conf in our code base. These confs are placed in the code base at a specified path to maintain a hierarchy while deploying many such applications.
Proxy Server To Route requests:
We had a proxy server( nginx) to route requests to different clusters and different namespaces. The proxy server registered different applications and after upstreaming identified application ,it routes the request to that particular app running in container. Thus enabling different cluster deployments an isolated behaviour running in different cluster and namespaces. It is the job of our proxy server to correctly route a request to the specified container .
Naukri Deployer and Endpoints:
As we have our own deployer for deploying multiple applications in single namespaces so for database services and other services like elastic we had our endpoints defined. And at these end points we had our services up and running.
Code for endpoint definition for each app’s cluster:
{
“kind”: “Endpoints”,
“apiVersion”: “v1”,
“metadata”: {
“name”: “app1-db”,
“namespace”: “{{NAMESPACE}}-{{ENVIRONMENT}}”,
“labels”: {
“app”:“db-endpoint”,
“appname”: “app1-db-endpoint”,
“team”: “myTeam”,
“environment”: “{{ENVIRONMENT}}”,
“type”: “db”,
“tier”: “backend”,
“release”: “{{RELEASE}}”
}
},
“subsets”: [
{
“addresses”: [
{ “ip”: “10.11.12.13” }
],
“ports”: [
{ “port”: 9999, “protocol”: “TCP”}
]
}
]
}
The NAMESPACE here corresponds to the namespace defined while deploying and ENVIRONMENT can be dev.test, cluster or any other .
Also the RELEASE corresponds to the branch or tag you want to be deployed.
The endpoints need not be confined only to database services running but also to any other service like elastic ,redis etc.
Thus going into abstraction we can say that our namespace will be having multiple pods running and each pod will have multiple containers communicating with each other which is done through shared file system or loopback network interface.
The containers running in different pods were connected via flannel, this is how we achieved networking between different containers running.
There can be multiple applications deployed in single namespace , but if a developer wants to deploy his/her applications in shared env ie there will be deployment of only his/her application and rest will be pointing to the stable images of applications running in one stable namespace.
Benefits for Naukri:
- Scalability:
Every developer gets his own environment(cluster) and is independent of other releases . Say, there are 20 applications and 100 developers then instead of deploying 100 * 20 containers there will be 100 *1 + 20 containers as each developer will be deploying his/her application only and rest will be pointing to the latest stable releases deployed already.
- Continuous Deployment:
As other application’s stable releases are deployed so any changes going live will be automatic in those releases.Whenever there is any change that goes live it is deployed and hence all applications will get updated releases of rest of the other applications.
- Robustness:
Whenever any application goes down or it’s container is not running then it is again restarted ,monitoring is done through kubernetes.Thus our overall system is self healing and self sufficient.
What’s next :
Our application environment basically consists of two parts.
- Master Environment
In this we have all the applications deployed with their stable releases deployed and is same for all users. - Shared Environment:
This environment is specific to a user and here the user overrides the master release of his/her application with his/her tag of applications and thus the environment is shared.
How we achieved this and how are applications are deployed and monitored in shared environment will be discussed in the next blog.



 The All-New Naukri iOS App (6.0)
The All-New Naukri iOS App (6.0)