

1. Introduction
Elasticsearch is a search engine. It provides a distributed full-text search engine over schema-free JSON documents.
As we all know Elasticsearch is a great product to index and search through a large number of documents. It supports various functionality like term and range queries, full-text search and aggregations on large data sets that are very fast and powerful. It is built over Lucene which is a high-performance, full-featured text search engine library written in Java.
When we are indexing data, the world is rarely simple as an independent data existing in isolation, there are cases when it is required to keep as relational data. Sometimes, it’s better to denormalize data into the children.
Because if we don’t denormalize it, there will be a redundant data in all the documents. One of the best examples would be, if you had a blog site data then you wouldn’t want to repeat the entire content of the blog post in each comment as this would vastly increase the amount of indexed data.

One option is to put child document inside the parent like shown in Fig 1.
One drawback here is that adding a child document will lead to the re-indexing of the entire document
2. How to Denormalize documents
Elasticsearch provides two concepts that help with this which are:
- Nested Document /Query
- Parent & Child Relationship.
We will be discussing more on the Parent Child Relationship.
3. Parent & Child Relationship
All that is necessary to establish the parent-child relationship is to specify which document type should be the parent of a child type. You’ve got to do it either at index creation time or with the update mapping API before the child type has been created.
As example: This is the very basic schema example of what we have implemented in First Naukri as parent-child, Where parent is the Institute and Child is the student

3.1 How Parent-Child Index different from other strategies:
Relationship support is available in Lucene since its version 3.4.
There are 2 different types of relationship:
- Indexing time Join.
- Query time Join
3.1.1 Indexing time:
This is a block indexing, where a block of documents will be added to the index and in which parent is the last block.
Each document will get sequentially assigned Lucene document id.
Lucene : IndexWriter#addDocuments()
But this comes with a clause that any change in the child or parent will lead to re-index the whole document block.
* Segment merging will not re-order the documents in the segment.
In Elasticsearch this type of join/relationship is exposed as Nested objects.
3.1.2 Query time:
As the name suggests this is a query time join, it is more expensive but provides a wide range of flexibility.
It doesn’t require any block indexing, so there is no such clause to index all parent-child if any of them changes.
While query time, you can either search from parent to child index or vice versa.
Query time is executed in two phases:
This query will execute on child indexes and all the ID’s from children are used to filter the parent. (in case of has_child query ) .
The pre-requisite of this kind of query is that the children must be correctly indexed in the shard of their parent.
So special precautions must be taken to fetch, modify, and delete them if the parent(ID) is unknown.
Parent-child relationship act’s similar to the Foreign key relations in RDBMS,
But this relationship comes with some limitation:
- A parent for the type is required if you are defining children.
- To reduce networking and increase in performance the relationship between child and parent is done in a shard, instead of distributing it on all the clusters.
The query consumes a huge amount of memory because it requires you to fetch all child IDs.If the count of parents is less, so it is recommended to use has_parent query. Elasticsearch uses _parent field to built an id cache which makes parent-child query/filter fast.
3.2 Indexing and Search Queries Example:
Elasticsearch holds both the parent and child data in the ram and computes the real time relationship.
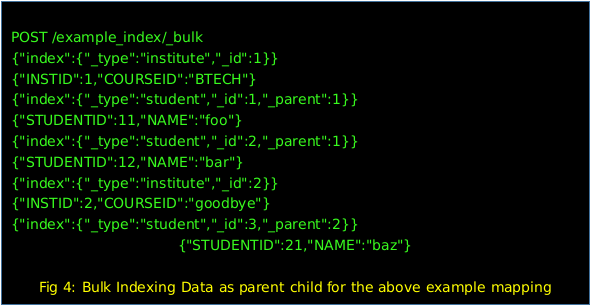
Both of these documents are now associated with the ‘Institute’ parent document, which allows you to use special queries such as:
- Has Parent Query: which works on parent documents and return children.
- Has Child Query: which works on child documents and return parent.
- Top Children Query: which performs a query and return top X matching children.
Has Child Query with sort on a number of child documents:
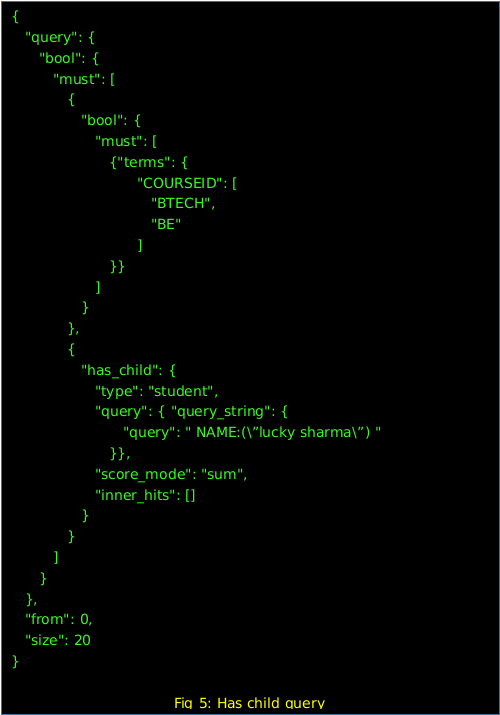
Here the result set will be the institutes who have the student name “lucky sharma” from courses BTECH or BE
3.3 How/When is it better than other strategies
In this kind of strategy:
- Children are stored separately from the parent, but are routed to the same shard. So parent/children are slightly less performance on read/query than nested.
- Updating a child doc does not affect the parent or any other children, which can potentially save a lot of indexing on large docs
- We get to maintain all the relationships
3.4 Cons of using Parent-Child Relationship
The downside is that Parent/Child are slightly less performant than Nested. The children docs are routed to the same shard as the parent, so they will still benefit from shard-level caches and memory filtering. But they aren’t quite as fast as nested since they are not co-located in the same Lucene block. There is also a bit more memory overhead, since Elasticsearch needs to keep an in-memory “join table”, which manages the relations.
4.Things to keep in mind before implementing Parent-Child Relationship in Elasticsearch
- Complex queries will slow down the search as Elasticsearch performs parent-child join in memory.
- Need to identify what entity needs to be a parent and what needs to be a child.
- Whether to have child and parent entities and not as a nested object.



 The All-New Naukri iOS App (6.0)
The All-New Naukri iOS App (6.0)