

Ever wondered what Crawling is all about, here, at Naukri? Why don’t we just use any generic crawler or Why do we even crawl in the first place?
We crawl jobs posted in the career sections of companies, to ease the pain of Recruiters. Instead of posting jobs manually, we help recruiters by pulling jobs programmatically from their career sections. The crawler crawls jobs from websites based on client requests.
Now, a bit about Crawling :-
A Web crawler is a computer program that browses the World Wide Web in a methodical, automated manner or in an orderly fashion. We do not need to crawl and index the whole web, but only job vacancies. So, what we need is a Focused crawler(or Topical crawler).
As opposed to a generic web crawler which is used for very high volumes, a focused crawler/spider, in most of the cases, delves into the sources to crawl and retrieve data that is not easy to find, and owing to complex page structures such as AJAX and other crawling hindrances, it is even beyond the reach of the search engines! But in most cases this is the data that is of utmost importance.
A focused crawler allows users to dig in deep into the web (Deep web) to mine useful data – based on topics of interest. It’s useful when we need to download only the relevant pages on the basis of a pre-defined topic, sources or a set of topics.
Deep Web is the search term referring to the content on the World Wide Web that is not indexed by standard search engines. The content is generally dynamic and behind the search forms, where someone has to perform actions like filling the search criteria, selecting the various drop-downs etc to fetch results.
So what are the Real Challenges?
Every site is different from the other in terms of structure, design, content, navigation, technology etc. Hence the questions arise :-
- How can we perform deep crawling of dynamic content on the web and unveil information on job vacancies buried under multiple layers?
- How can we handle dynamic HTML pages along with the static ones?
- How can we handle Websites made in JavaScript and / or involving AJAX calls?
And Above all,
- How can we build a generic system to extract job information from this heterogeneous web world?
THE APPROACH :-
What if, a site can be added by writing simple navigation and extraction rules.
What if, we mimic a Web Browser? It knows everything about a Web Page.
And Above all,
What if, we provide a simple utility for rules addition in the process of site discovery itself i.e while browsing a site through mozilla or chrome. The utility generating and understanding the rules by itself as the user browses.
So that, This utility can be used by non-techies or the ones with less technical knowledge (like someone from operation team).
THE SOLUTION :-
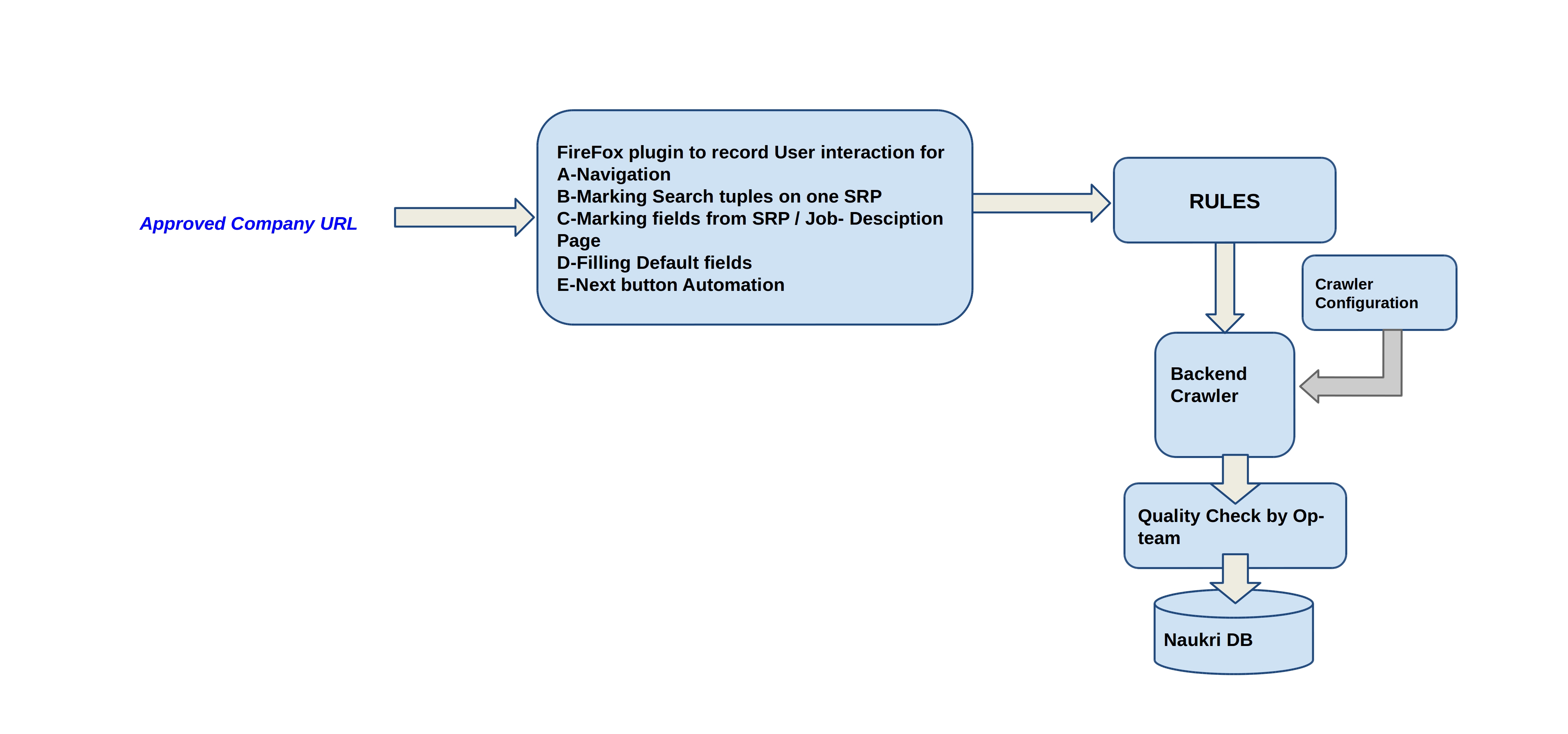
A Firefox extension (The utility):-
A Firefox-addon to record user activity for the candidate website. The user
- records navigation of pages,
- selects one search result tuple,
- trains the pagination architecture,
- selects individual fields for extraction from a single Job description page.
The Crawler :-
Then comes the role of “The crawler”, a backend application, which runs on recordings generated by “The utility”.
- The recordings are inert till “The crawler” adds magic into it.
- Search Forms are being backed by data dictionaries to get filled.
- Algos for
- Rebuilding of Xpath of an Element, selected using any locator.
- Scraping similar Elements based on their relative Xpaths and Class-Names.
- Identifying uniqueness in each job to avoid redundancy.
- Machine Learning Classification / Prediction of fields.
- Rule based, Machine Learning based extraction.
- Identifying Popups, I-frames, handling multiple browser windows.
- A multi-threaded application, runs multiple sites in parallel.
- Real user clicks are simulated to execute corresponding actions or events attached to the clickables.
- Various selenium methods are overridden to create our own wrapper functions. e.g. Click, Select etc.
Overall, the user trains the system for one job and system runs for all possible jobs available on that site.
Tools / Technologies: Java, Perl, PhantomJS, firefox, Selenium, Xpath, CSS, Regular Expressions, MySQL, XML, Machine Learning.
The Conclusion:-
So, the above system solves the problems of ‘crawling deep web’ and of ‘having technical expertise to add sites for crawling’.
But What if we can automate the whole process, leaving no scope of any manual effort?
What if the crawler auto-generates the rules using its own intelligence?
A solution where only site url is required as an input. And, the rest is done by the crawler, which intelligently picks all the jobs from the sites, irrespective of variations across websites.
Will love to share but you have to wait for the next blog in this series.
Till then keep reading… 🙂
Feel free to comment below for queries/feedbacks.



 The All-New Naukri iOS App (6.0)
The All-New Naukri iOS App (6.0)
Nice and insightful post. Looking for more posts like this.