

This is about using a great tool in a better way. UIMA is a framework and world wide standard for text analytics applications. UIMA is being used for text extraction / annotation in a number of applications. We built an information extraction service using UIMA framework .
It’s an online service, expected to be efficiently functional, scalable and consistent in a multi-threaded high concurrency environment. Unfortunately it wasn’t.
UIMA : Extraction Framework
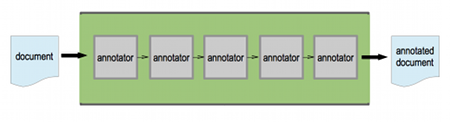
UIMA, an apache technology, is a framework and standard for text analytics applications. It allows to analyze large volumes of unstructured information in order to discover knowledge that is relevant to an end user. Framework allows you to break analytic task into annotators and you get an analysis engine as a pipeline of these annotators.
Where it all started : (A nightmare)
-
We had a single instance of analysis engine(AE) shared between each request thread.
-
Each request has its own Common Analysis system (CAS) object (handler for the document input and parsed output).
-
A high number of dictionaries (large in size) are being used for annotating various fields
-
Unfortunately, this architecture failed on a little high concurrency.
-
And we realized, neither AE nor ConceptMapper is thread safe. Although new CAS was being created with each request, it was not sufficient.
Possible solutions :
-
Least painstaking solution was to make overall document processing synchronized. And UIMA framework itself suggested this solution for multi-threaded environment. But we weren’t satisfied because ultimately we were still processing only one document at a time.
-
The other solution was to have a Object pool of fixed number of AE instances in-sync with CAS object pool. It seems the solution but on the stake of high memory usage as now we will have multiple copies of huge data sets.
And it ends (The Ultimate Solution)
-
We were not content, so we looked into the problem more deeply. As now the problem converted into memory usage, we took heap dumps and thread dumps for the service at different points of time and different number of AE instances. We analysed the memory usage and thread blocking.
-
The dictionaries, CAS’s and AE’s were using the most memory. Incidentally the objects using the most memory were also the ones which were blocking the threads.
-
As CAS instances use memory and take some time to construct, its better to have separate pool for CAS instances as well.
-
We separated all the light weighted state objects from Dictionary objects and made Data dictionary objects as shared resources between multiple AE’s.
-
Pool sizes for AE, CAS are configurable and on the basis of resource availability on machines / product requirements, we can now control the concurrency.
Thus, we can now process multiple documents simultaneously, completely thread-safe with almost similar memory usage as for single threaded system. This solution seems promising and we are further evaluating UIMA asynchronous scale-out for added advantage over the current architecture.
Related Posts
Posted in General



 The All-New Naukri iOS App (6.0)
The All-New Naukri iOS App (6.0)