

“There’s ALWAYS a way to fix something.”
–Steven Wolff
And when you are using PHP, there are multiple ways to fix something. What we need to determine is, that which way is the best. Computation is not like solving a maths problem, where simplicity can be determined by the number of lines. Computation requires resources, for example CPU Cycles and memory. Now when we have got multiple ways to solve a problem, we need to think in terms of computation and how much resources it will take.
The objective is to accomplish the task in minimal number of steps, but different functions in PHP have varying amounts of underlying code. So we need to pick the best among them, so that it consumes less resources. To compare such functions, we have given preference to the execution time of these functions. We can afford to give some extra memory, but can not make the users of our product wait longer than required. The issue of time complexity does not bother when the amount of computation is less, like in tens or hundreds. Two functions having complexity n^2 and 2^n will not affect us when size of n is very less. But what if size of n is very large, then we need to think of time constraints. Hence to check which function in PHP requires less time than other functions designed for similar tasks, we have compared the execution times of functions.
For comparison, we have created our own benchmark function, which will give more accurate results as compared to existing benchmark functions available, because execution of these type of functions is platform specific, so its always better to use your own benchmark function to compare.
We have determined some of the techniques while using php which can help us to make an optimized application. You can find these techniques and methods with comparison as under:
1. If we can declare a method static, declare it static, Speed upswings by a factor of 4.
2. Do not use functions inside of for loop, such as for ($x=0; $x < count($arr); $x) The count() function gets called each time.
3. Incrementing an undefined local variable is 9-10 times slower than a pre-initialized one.
4. Methods in derived classes run faster than ones defined in the base class.
5. Using single quotes ( ‘ ‘ ) is faster than using double quotes( ” ” ) if you are going to keep only the string inside it avoiding any variables.
6. Use “= = =” instead of “= =”, as the former strictly checks for a closed range which makes it faster.
7. Disable Debugging Messages before going live, File operations are expensive.
8. Reduce Number of Hits to DB.
9. It’s better to use switch statements than multi if, else if, statements.
10. Keep most frequently used switch cases on the top.
So the performance of functions which perform similar tasks is calculated. The results are listed as follows:
- Analyzed (isset, empty, is_null, $var==null, !$var)
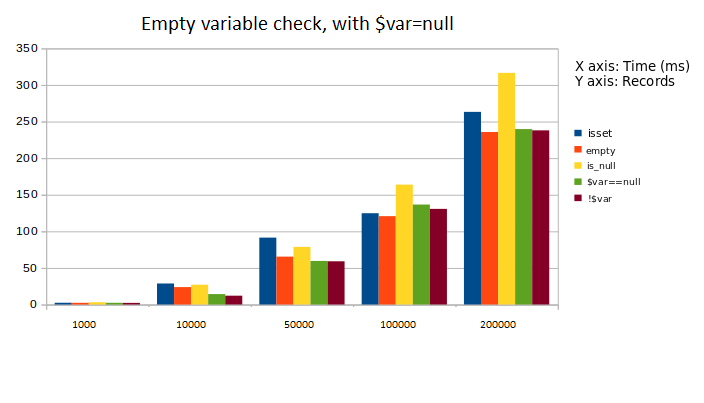

Note: We compared five functions which check whether a variable is empty/null or holds some value. The observation was that for small data sizes, the difference in their execution time was not very much. But when we think about scalability, the change in execution time differs by bigger amounts.
Both cases, (i.e. variable taken as null and not null) were considered. First graph is for a null variable and second one is for a variable with some not null value.
Observation: is_null() is the slowest and empty() is the fastest.
Suggestion: Use empty() and avoid is_null if it is to be used on large scale
2. Analyzed (count(), ===, empty(), bool)
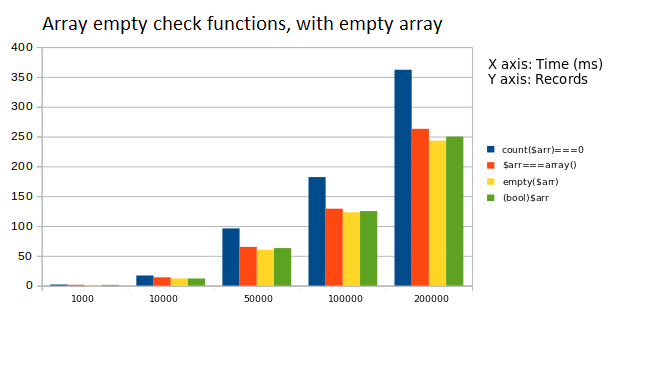
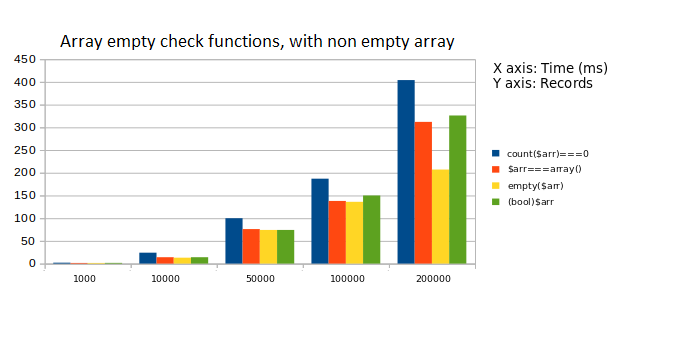
The first graph represents the execution time when array taken was empty. In the second graph, the array in consideration contained few elements. The time taken by a function to check non empty arrays was generally more than that of empty arrays.
The general observation is listed as follows:
Observation: empty() works best again, and count() is the slowest
Suggestion: Avoid using count(), use empty()
3. Analyzed (==, ===, strcmp(), !strcmp, strcasecmp)
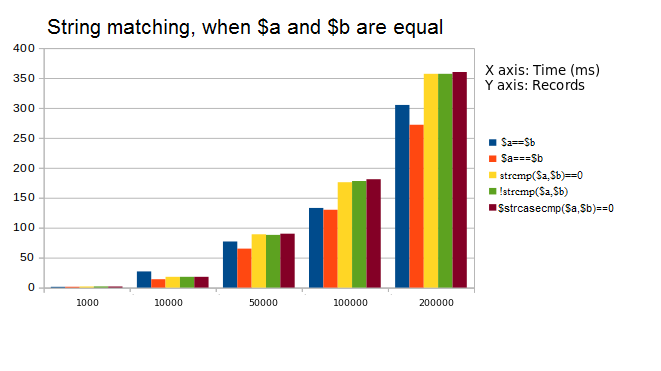

Again two cases, one with same set of strings and other with different strings are considered. First graph represents the case when two strings are equal. The second graph represents execution time of the functions on unequal strings.
Observation: Direct comparison works best. Notice the blue and orange bars and see the difference.
Suggestion: Use === instead of == wherever applicable.
Avoid using strcmp/strcasecmp.
4. Analyzed (strstr, strpos, stristr, preg_match, ereg)
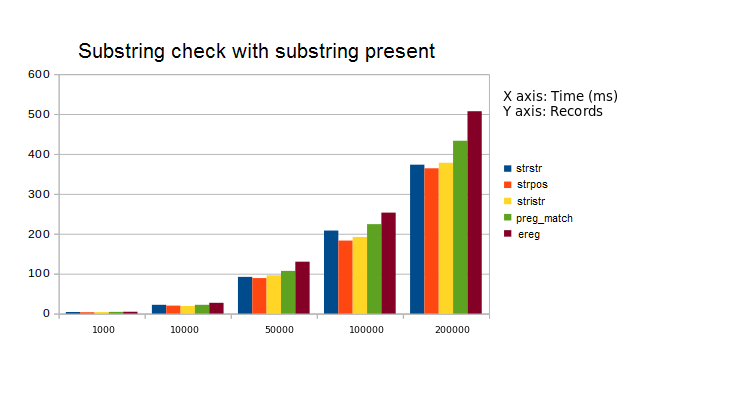
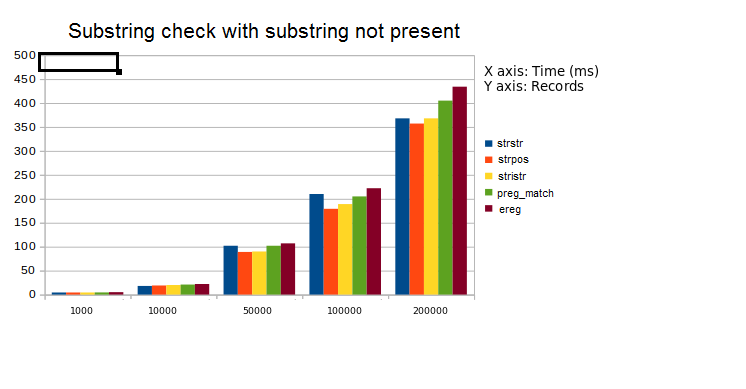
The first graph represents execution time when substring was present. We have considered the worst case when substring was present at the end of the superstring. The second graph represents the case where substring was absent.
Observation: strpos works best while preg_match and ereg perform very slow.
Suggestion: Use strpos to determine whether a string is substring of another.
5. The last but not the least: array_merge is slow, VERY SLOW
While comparing the time of various functions, we calculated the run time of array_merge with different data sizes. The results were very surprising. For processing 200000 records, the function took 27 minutes, which is very slow. Even the above results shown in the bar chart are in milliseconds and they do not cross even 1 second for that data size. But array_merge took way more time.
Here is the result of array_merge execution time on different data size
|
|
10000
|
25000
|
50000
|
100000
|
200000
|
|
array_merge($arr, $x)
|
2 seconds
|
19 seconds
|
96 seconds
|
420 seconds
|
27 minutes
|
So, instead of using array_merge, we can simply run a loop for each record of the array $x and add it into new index of $arr
Eg: pseudocode
———————–
for i = 0 to x
$arr[]=$x[$i]
———————–
Provided, the arrays are non-associative.
The result using such approach is amazing:
|
|
10000
|
25000
|
50000
|
100000
|
200000
|
|
$arr[] =$x
|
0.004 seconds
|
0.028 seconds
|
0.03 seconds
|
0.034 seconds
|
0.609 seonds
|
If you observe it graphically, the complexity increases exponentially:
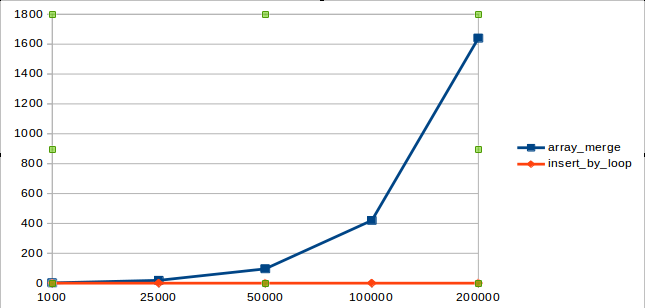
The orange line represents the normal insertion by loop. It coincides with the X-axis because its execution time is less than 1 second.



 The All-New Naukri iOS App (6.0)
The All-New Naukri iOS App (6.0)
Hi ,
For your merge_array i got result which are much different than yours .So I am putting my code for associative and non-associative array and their time. If I have done some thing worng in my code,Please let me know.
associative array
time = 0.83166;
//non associative array
time = 0.518886
associative array
for($i=0;$i<2000000;$i++){
$ren1 = rand();
$ren2 = rand();
$arr1[$ren1][$ren2]=$i.$ren1.$ren2."a"."$i+1";
$arr2[$ren2][$ren1]="$i+100".$ren1.$ren2."a"."$i+3";
}
$time = microtime();
$result = array_merge($arr1, $arr2);
$t2 = microtime();
echo $t2-$time;die;
//non-associative array
for($i=0;$i<2000000;$i++){
$ren1 = rand();
$ren2 = rand();
$arr1[]=$i.$ren1.$ren2."a"."$i+1";
$arr2[]="$i+100".$ren1.$ren2."a"."$i+3";
}
$time = microtime();
$result = array_merge($arr1, $arr2);
$t2 = microtime();
echo $t2-$time;die;
time = 0.518886
Consider the scenario where you have to fetch some records from database. Its not advisable to fetch a large number of records in one shot, so you decide to fetch records in chunks repetitively, in batches of small numbers, in a loop.
Now when array_merge is required in this scenario (for example to store all the records in an array), then array merge has to be in this loop where you're fetching the result in chunks.
In this scenario, processing time of array_merge increases exponentially. The time we are showing in this post represents the above scenario.
Even if you don't do this and perform array_merge (as you are doing, not in a loop as ours), array_merge is generally slower than adding elements one by one. Your result surely will have a vast difference from ours, but in general, array_merge is slower than the latter method. Please note that the modified method only works for non-associative arrays.
The pseudocode we have used to compare array_merge is as follows:
$parent, $chunk
while(true)
$chunk = [fetch chunk from Database] ***
$parent = array_merge($parent, chunk);
if(count($chunk) becomes 0)
break;
***Note: we are not actually fetching the array $chunk from the database, but merging the array $chunk in a loop, assuming that it is coming from the database, which represents the scenario where this can happen (If it fetches from database, it will take even more time).